
For those who know the basics of machine learning (ML) know that overfitting and underfitting are two huge problems in ML. It consistently degrades the performance of the ML models.
Think about it:
The primary goal of ML models is to adapt to the given set of unknown inputs and provide suitable output. You can only get reliable output after you train the ML model on multiple datasets. It also helps us make predictions about a piece of data that the model has never seen.
Sometimes, the model trains too much; sometimes, it trains too. This is where overfitting and underfitting comes in. They’re solely responsible for the poor performances of ML algorithms. Let’s get into the details.
What is Overfitting and Underfitting in Machine Learning?
Overfitting and underfitting are two sides of the same coin. They both come with its own set of challenges that can hinder the performance of your models. Let’s see what each means in the context of machine learning.
1. Overfitting: When Your Model Learns Too Much
Imagine teaching someone to recognize a cat by showing them only black cats. If they start thinking all cats must be black, they’ve overlearned from the examples provided. This is overfitting in a nutshell.
In ML, overfitting happens when your model captures the underlying pattern along with the noise and random fluctuations in your training data.
As a result, even if the model performs incredibly well on this training set, it frequently struggles to generalize to new, untested data.
2. Underfitting: When Your Model Learns Too Little
Underfitting happens when your model is too simple to effectively capture the underlying trends of the data. Returning to our earlier example, it’s like teaching someone about cats using only vague descriptions. They might not recognize a cat when they see one.
In technical terms, underfitting occurs when there’s still room for improvement on the training data itself. This model is not complex enough to learn from the data adequately.
What are the Reasons for Overfitting
Below are some primary reasons why overfitting occurs
- When Your Data Used for Training Contains Noise: When the training data includes errors or irrelevant information (often referred to as ‘noise’), the model might learn these inaccuracies as if they were significant features.
- When Your Model Has a High Variance: A model with high variance pays too much attention to the training data. It also captures the general trend and random fluctuations.
- When the Model is Too Complex: Complex models with many parameters are particularly prone to overfitting, especially if the training data is limited. These models are capable of learning very specific patterns in the data, but these patterns often do not apply to new data.
What are the Reasons for Underfitting?
Here are some of the key reasons why underfitting happens:
- When There’s Insufficient Model Complexity: When a model is too simple, it lacks the capacity to learn from the data effectively. This could be due to using linear models for non-linear data problems or not having enough parameters to capture the relationships within the data.
- When Your Data Features are Limited: Underfitting can also stem from not using enough input features (variables) to make predictions. If critical features are missing from the model, it won’t capture important elements that influence the target variable.
- When There’s Too Much Regularization: While regularization is a technique used to prevent overfitting, setting it too high can lead to underfitting.
Detect Overfit Models: What are the Tell Tale Signs
One effective way to identify overfitting is by testing the model on a new set of data that represents a comprehensive spectrum of possible input values and types. Here are a few methods to identify overfit models:
1. K-Fold Cross-Validation
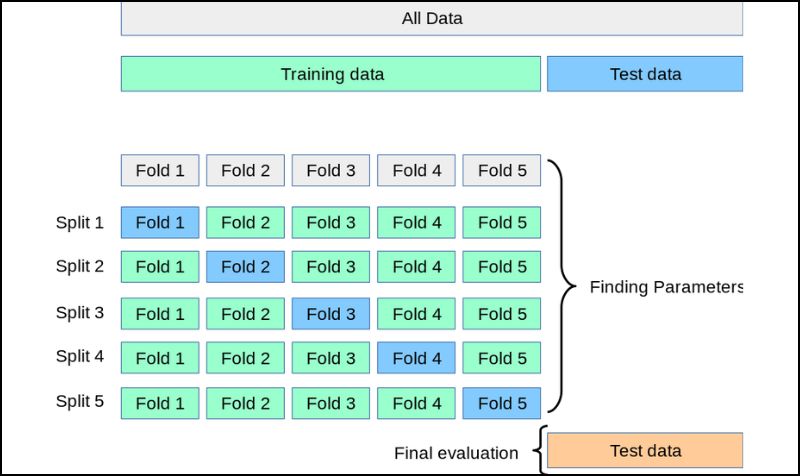
Source: Scikit learn
K-fold cross-validation is a widely used method for testing machine learning models to detect overfitting. Here’s how it works:
a. Divide the Training Data: Split your entire training dataset into ‘K’ equally sized segments or folds.
b. Iterative Training and Validation:
- In each iteration, set aside one of the K-folds as the validation data and use the remaining K-1 folds as the training data.
- Train your model on these K-1 folds.
- Evaluate the model’s performance on the validation fold set aside.
c. Performance Scoring:
- After training, assess the model’s performance based on the quality of predictions it makes on the validation set.
- Note the performance score for each iteration.
d. Average the Scores: Once all iterations are complete, calculate the average of the performance scores from each iteration. This average provides a robust measure of how well your model is likely to perform on unseen data.
2. Train/Test Split
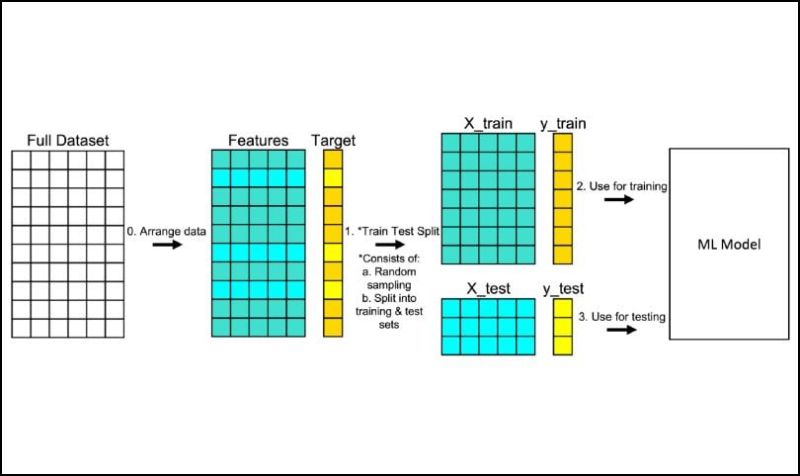
Source: Builtin
One straightforward method is to divide your data into a training set and a testing set. Generally, data scientists reserve a portion of the training data as test data, specifically to check for overfitting. If the model performs significantly worse on this test data than on the training data, it’s likely overfitting.
This method is simpler than K-fold cross-validation but can be less robust because the performance might depend heavily on how the data is split.
How to Overcome Overfitting?
Overfit ML models tested on new, unseen data is a headache for most ML engineers, and data scientists. Fortunately, several strategies can help mitigate this issue:
1. Early Stopping
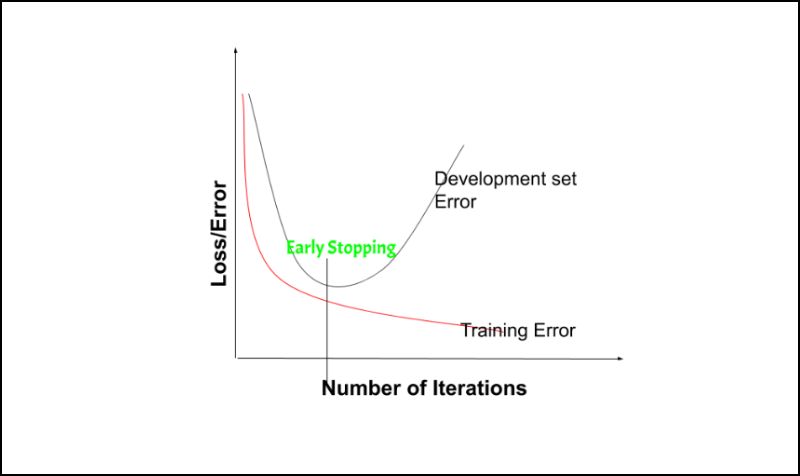
Source: Geeks for geeks
Think of early stopping as calling a timeout during training. If you keep training your model for too long, it starts to learn all the random noise in your data as if it’s important. By stopping the training early—when the model starts doing worse on new data instead of better—you prevent it from getting confused by that noise. Just make sure you stop at just the right time, not too soon and not too late.
2. Pruning (Feature Selection)
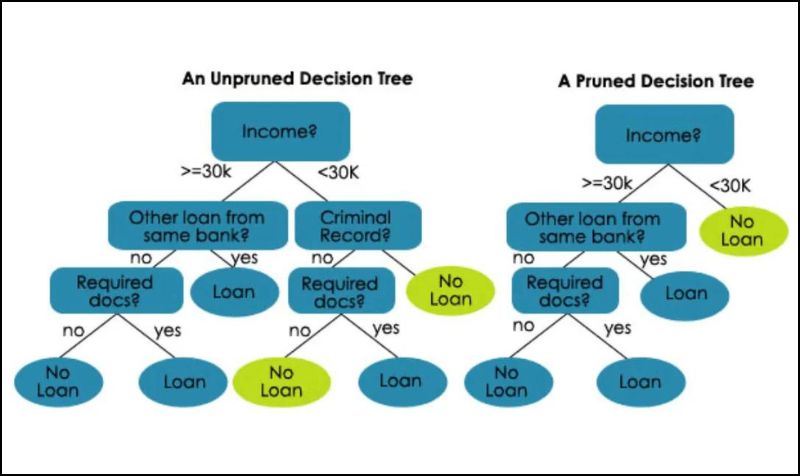
Source: Medium
Pruning is about cutting out the fluff. Not everything you have on your dataset is needed for making predictions. Say you’re trying to tell if a photo is of an animal or a person. Here, you’ll need to train the model on the big clues like the shape of the face, not small stuff like the color of the eyes. Basically, you must try to keep the irrelevant details out while training the model.
3. Regularization
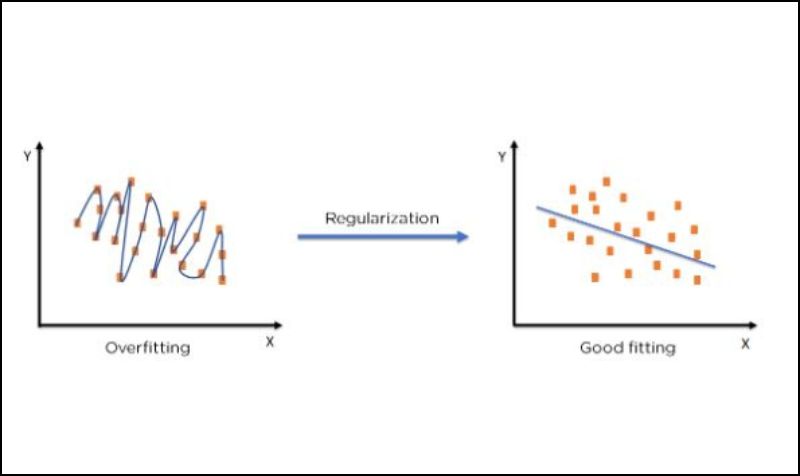
Source: Analytics vidya
Regularization is like giving your model a reality check. It adds a little penalty for every extra detail the model tries to learn. This way, the model doesn’t go overboard trying to fit every single dot and comma in the training data.
4. Ensembling
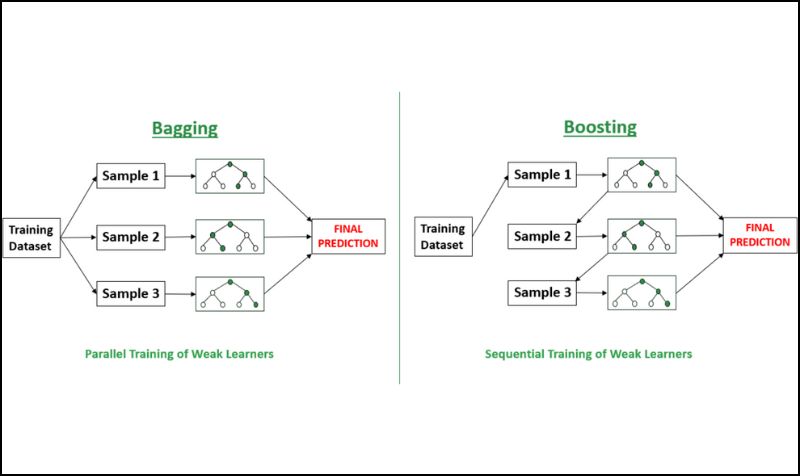
Source: Geeks for geeks
This simply means you’ve got to use different models to get a better answer. Some models might get things wrong, but when you put them together, they help correct each other’s mistakes. There are two main ways to do this:
- Bagging: This is where you train lots of models on little chunks of your data and then average their answers
- Boosting: It’s where each new model builds on the errors of the last one to improve continuously.
What is a Good Fit in Machine Learning?
A model with a good fit is versatile and reliable. It means that you can trust the model to make predictions or decisions in real-world applications, not just under controlled training conditions. A good fit in ML is when you strike a balance between complexity and simplicity. It occurs when a model:
- Performs accurately on training data
- Performs well on new, unseen data
- Remains effective and accurate even with minor changes or variations in the data
- Achieves a balance between bias (oversimplification) and variance (overcomplication)
Learn about Overfitting and Underfitting with IEEE BLP’s Machine Learning Course
This self-paced course provides a robust introduction to the fundamentals of machine learning alongside the advanced techniques that are shaping the future.
From the basics of Python programming with libraries like NumPy and Pandas to more complex topics like neural networks and image analysis with CNN, this machine learning course has everything you need to start applying machine learning in various domains.
Course Highlights
- Introduction to Essential Programming Tools: Get hands-on with tools that are foundational in ML (programming languages and libraries)
- Deep Dive into ML Techniques: Explore key ML techniques such as regularization, support vector machines, and neural networks.
- Practical Applications: Learn through practical scenarios in natural language processing (NLP), recommender systems, anomaly detection, and more.
- Fundamentals to Advanced Learning: Whether you’re starting or looking to deepen your understanding, this course offers material from basic to advanced levels.
Who Should Enroll?
This course is perfect for everyone, from aspiring candidates to working professionals to AI enthusiasts. It is perfect for tech pros, newcomers, or anyone interested in exploring what makes AI tick.
In Conclusion
Understanding overfitting and underfitting is crucial for those who want to make a career in ML. Mastering these concepts will equip you better to tackle real-world challenges and enhance your predictive models.
Whether you’re a student, industry professional, or academician, delving deeper into machine learning through our courses can unlock new opportunities and insights.
Ready to take your machine learning skills to the next level? Enroll in our comprehensive machine learning course today!
FAQs
1. What is overfitting in machine learning with an example?
Overfitting occurs when your model is a great student who memorizes every word from the book but struggles to answer questions that are not directly related to the text.
2. How do you define overfitting?
Overfitting is when your model learns the details and noise in the training data to the extent that it negatively affects the performance of new data.
3. What is overfitting and underfitting in ML?
Overfitting is when your model knows the training data too well, including its errors; underfitting is when it doesn’t learn enough from the data, missing the key patterns.
4. How do I know if my model is overfitting?
You’ll know your model is overfitting if it performs really well on the training data but poorly on any new, unseen data.
Leave a Reply